Abstract
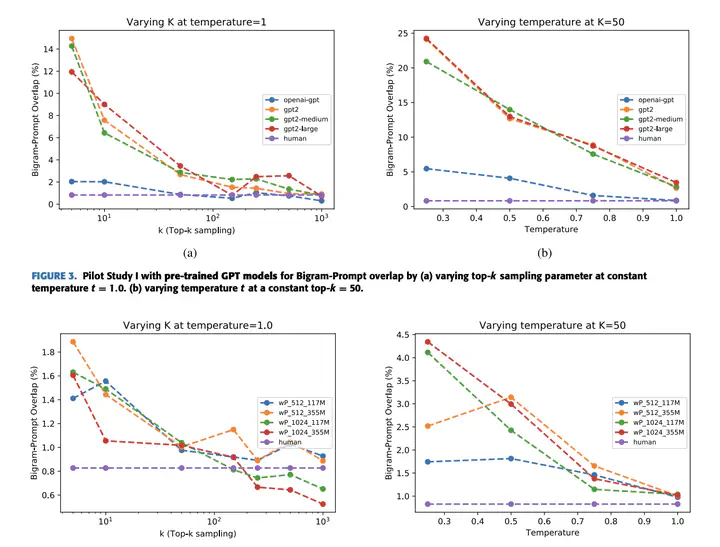
Massive textual content has enabled rapid advances in natural language modeling. The use of pre-trained deep neural language models has significantly improved natural language understanding tasks. However, the extent to which these systems can be applied to content generation is unclear. While a few informal studies have claimed that these models can generate ‘high quality’ readable content, there is no prior study on analyzing the generated content from these models based on sampling and fine-tuning hyperparameters. We conduct an in-depth comparison of several language models for open-ended story generation from given prompts. Using a diverse set of automated metrics, we compare the performance of transformer-based generative models – OpenAI’s GPT2 (pre-trained and fine-tuned) and Google’s pre-trained TransformerXL and XLNet to human-written textual references. Studying inter-metric correlation along with metric ranking reveals interesting insights – the high correlation between the readability scores and word usage in the text. A study of the statistical significance and empirical evaluations between the scores (human and machine-generated) at higher sampling hyperparameter combinations (t = {0.75, 1.0}, k = {100, 150, 250}) reveal that the top pre-trained and fine-tuned models generated samples condition well on the prompt with an increased occurrence of unique and difficult words. The GPT2-medium model fine-tuned on the 1024 Byte-pair Encoding (BPE) tokenized version of the dataset along with pre-trained Transformer-XL models generated samples close to human written content on three metrics: prompt-based overlap, coherence, and variation in sentence length. A study of overall model stability and performance shows that fine-tuned GPT2 language models have the least deviation in metric scores from human performance.
Add the publication’s full text or supplementary notes here. You can use rich formatting such as including code, math, and images.
Avisha Das
Research Fellow
My research interests include natural language understanding and generation with a focus on Biomedical NLP and AI Security.